SREcon19 EMEA
October 2nd - 4th, 2019 – Dublin, Ireland
Full program: https://www.usenix.org/conference/srecon19emea/program
Venue photos



My personal favorites
In order of appeal.
- A Systems Approach to Safety and Cybersecurity
- Pushing through Friction
- One on One SRE
- Advanced Napkin Math: Estimating System Performance from First Principles
- Other close contenders:
All talks attended
In order of appearance.
The SRE I aspire to be
Yaniv Aknin, Google Cloud
https://www.usenix.org/conference/srecon19emea/presentation/aknin
- Engineering –> Using scientific methods. Requires measurements.
- SRE: Measuraby optimize revenue versus cost.
- Techniques in our toolbox:
- Redundant resources – trade cost
- Degraded results – trade quality
- Retry transient failures – trade latency
- The error budget steers reliability versus innovation.
- A really good SRE understands the business and can communicate with business leaders in their language.

A Systems Approach to Safety and Cybersecurity
Nancy Leveson, MIT
https://www.usenix.org/conference/srecon19emea/presentation/leveson
-
Current safety tooling is 50-60 years old. Assumes accidents are caused by individual component failures.
-
The problem (with safety) is complexity, mostly from interactions between different components.
-
Human error is inevitable. Human behavior is always affected by the context it’s in.
-
Nancy describes the old model of modeling reliability, and how it fails in modern (software) systems.
-
Nancy considers systems theory a possible way forward.
- Focuses on systems as a whole.
- Treat safety as a control problem (rather than a failure problem)
-
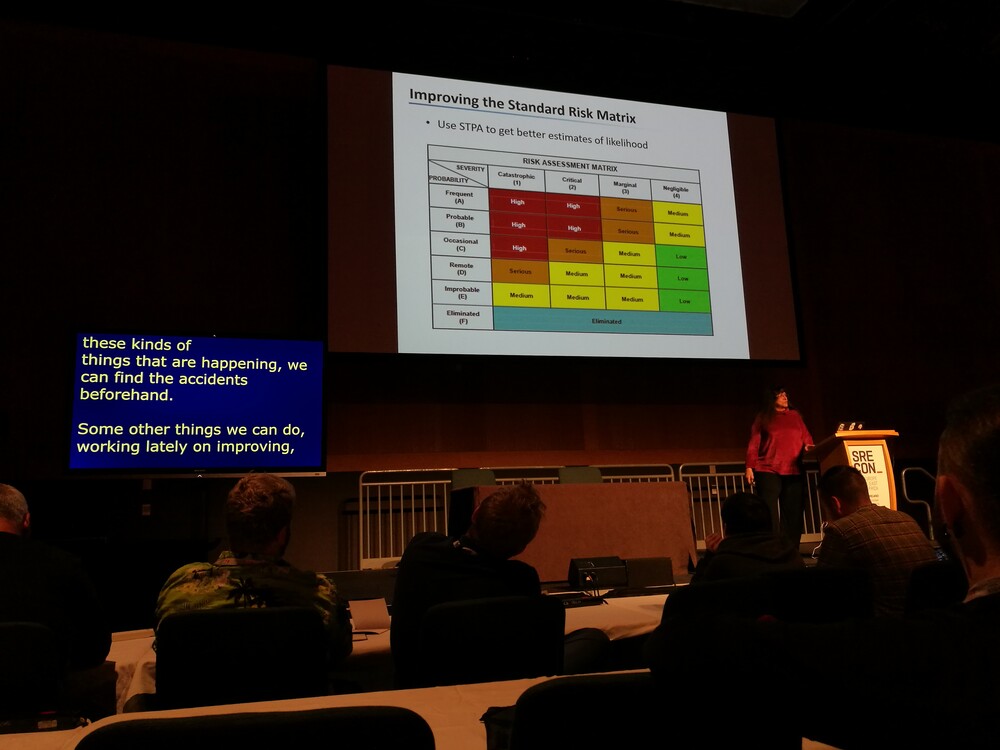
STAMP: Systems Theoretic Accident Modeling Process.
-
STPA: Systems Theoretic Process Analysis.
-
STPA is gaining industry adoption.
-
All of Nancy’s evaluations show STPA is better at identifying more critical requirements or design flaws and orders of magnitude cheaper.


A Tale of Two Rotations: Building a Humane & Effective On-Call
Nick Lee, Uber
https://www.usenix.org/conference/srecon19emea/presentation/lee
- Triage aggressively.
- Constantly refine alerts and thresholds
- Lack of mitigation resulted in a bad on-call experience.
- Quantify on-call.
- Tools need to be trustworthy and feel safe to use.
Latency SLOs Done Right
Heinrich Hartmann, Circonus
https://www.usenix.org/conference/srecon19emea/presentation/hartmann-latency
- Whole talk boils down to percentile metrics not being suited for SLOs because they cannot be aggregated (or have other math used on them)
- Possible solutions:
- Log data
- Counter metrics
- (HDR) histograms
- Personal note: With Prometheus this is clearly documented, with plenty of resources on how to use histograms for this type of data. Also, the speaker is quite a curious character.
Building a Scalable Monitoring System
Molly Struve, Kenna Security
https://www.usenix.org/conference/srecon19emea/presentation/struve
- Good intro story from Molly about their history/failures and the road to where they are now.
- Monitoring must-haves:
- Centralize alerts in 1 place.
- Make all alerts actionable.
- Make alerts mutable/silenceable.
- Track alert history.
- With a good system, developers began to contribute to and improve the monitoring system.
Being Reasonable about SRE
Vítek Urbanec, Unity Technologies
https://www.usenix.org/conference/srecon19emea/presentation/urbanec
- Rant against buzzwords and hype adoption.
- You probably already do parts of SRE.
- Shifting from Ops to true SRE takes time and effort.
- More problems happen on the dev side than on the infra side – so join them to learn about their issues.
From nothing to SRE: Practical Guidance on Implementing SRE in Smaller Organisations
Matthew Huxtable, Sparx
https://www.usenix.org/conference/srecon19emea/presentation/huxtable
- Complexity often creeps up on us.
- How do you navigate risk?
- “Embedded SRE” model doesn’t affect expected change.
- Dedicated team also doesn’t work. Gets out of touch or becomes a tooling team.
- Instead, make developers have control over and own their own stuff.
- Paper: the compliance budget.

My Life as a Solo SRE
Brian Murphy, G-Research
https://www.usenix.org/conference/srecon19emea/presentation/murphy
No notes.
All of Our ML Ideas Are Bad (and We Should Feel Bad)
Todd Underwood, Google
https://www.usenix.org/conference/srecon19emea/presentation/underwood
No notes.
Fast, Available, Catastrophically Failing? Safely Avoiding Behavioral Incidents in Complex Production Systems
Ramin Keene, fuzzbox.io
https://www.usenix.org/conference/srecon19emea/presentation/keene
- Forego correctness, embrace safety.
- Bugs may be incidents too.

Advanced Napkin Math: Estimating System Performance from First Principles
Simon Eskildsen, Shopify
https://www.usenix.org/conference/srecon19emea/presentation/eskildsen
- Effectively a talk about https://github.com/sirupsen/napkin-math, but highly recommended.
- “The goal of this project is to collect software, numbers, and techniques to quickly estimate the expected performance of systems from first-principles. For example, how quickly can you read 1 GB of memory? By composing these resources you should be able to answer interesting questions like: how much storage cost should you expect to pay for a cloud application with 100,000 RPS?”
- Want a monthly napkin challenge? https://sirupsen.com/napkin/
The Map Is Not the Territory: How SLOs Lead Us Astray, and What We Can Do about It
Narayan Desai, Google
https://www.usenix.org/conference/srecon19emea/presentation/desai
- Bad things happen when you over-simpliy
- SLOs are not static. Review them and update them as situations change.
- Document rationale for changes to SLOs.
- Important operations often happen at low QPS. Math/statistics doesn’t work well there.
- Set per-customer SLOs.
- Clearly communicate effects of service behavior changes.
Load Balancing Building Blocks
Kyle Lexmond, Facebook
https://www.usenix.org/conference/srecon19emea/presentation/lexmond
- DNS LBs
- Round-robin
- Anycast DNS
- Geo-aware
- Network-aware
- Latency-aware
- Caching problematic with DNS LBs.
- Anycast routing not always optimal.
- Facebook POPs deliberately use near-similar LBs to actual DCs.
- Maglev LBs (termed by Google)
What Happens When You Type en.wikipedia.org?
Effie Mouzeli and Alexandros Kosiaris, Wikimedia Foundation
https://www.usenix.org/conference/srecon19emea/presentation/mouzeli
- Wikimedia uses 2 primary DCs and 3 POPs at the moment.
- Kubernetes
- Calico
- Helm
- 2 clusters + 1 staging
- Message queues
- Kafka for everything
- Fun fact: Ping offload servers for all the people checking their connectivity



Refining Systems Data without Losing Fidelity
Liz Fong-Jones, honeycomb.io
https://www.usenix.org/conference/srecon19emea/presentation/fong-jones
- Two types of metrics
- Host metrics
- Per user/behavior metrics
- We need context with data
- Reducing costs
- Store less data
- Don’t store “read never” data
- One event per transaction
- Use tracing for linked events
- Sample your data.
- Sample traces together, not independently
- Aggregate data
- Destroys cardinality
- Cheap to answer known questions
- Inflexible/unsuitable for new/unknown questions
- Store less data
- When sampling:
- Adjust sampling dynamically
- Normalize sampling per-key
- Retain errors & slow queries

One on One SRE
Amy Tobey
https://www.usenix.org/conference/srecon19emea/presentation/tobey
- Trauma: Extreme stress which overwhelms the ability to cope.
- Example from GitHub is cited where personal breaks, relief, etc were stressed.
- One-on-one incident debrief advocate.
- Stresses informed consent. Let people know they can talk safely.
- Questions/agenda:
- Your role in the incident?
- What surprised you?
- How long did you work on the incident?
- Did you get the support you needed?
- Do you feel it was preventable?
- What actions do you feel good about?
- What could have gone better?
- What did you learn from this?
- What could we do to prevent re-occurrence?
- Did our tools and documentation help you?
- Did you practice self-care?
- Can you think of anyone else for me to talk to?
- Talking to people individually can build powerful, under the radar shadow networks.
- Empathy powerful way to affect organisational change (according to Hardvard Business Review).
Prioritizing Trust While Creating Applications
Jennifer Davis, Microsoft
https://www.usenix.org/conference/srecon19emea/presentation/davis
- It’s easy to postpone security until the end.
- Foundations: Defense in Depth.
- Threat modeling: Cheap and easy to do during early design.
- Architectural trade-offs.
- Linting/static code analysis.
- Secure Code Reviews.
- Plan for security violations.
- Don’t forget to talk to your vendors when spotting issues with them.
SRE & Product Management: How to Level up Your Team (and Career!) by Thinking like a Product Manager
Jen Wohlner, Livepeer
https://www.usenix.org/conference/srecon19emea/presentation/wohlner
- Know your users and talk to them.
- Do user interviews.
- Ensure diversity in roles, titles, etc.
- Ask non-leading questions.
- Hold prototyping sprints.
- Add user-centric goals to roadmaps.
- Idea: Monthly readmap meetings.
- The roadmap is an internal tool. Don’t just share it “as-is”, use bi-weekly emails/status updates for outside messaging.
- Follow-up with users regularly.
- Uses, painpoints and needs change over time.

Building Resilience: How to Learn More from Incidents
Nick Stenning, Microsoft
https://www.usenix.org/conference/srecon19emea/presentation/stenning
- Why learn from incidents?
- Prevention is the common answer, but..? Read How Complex Systems Fail
- Human error is a symptom, not a cause.
- Avoid counterfactual reasoning during investigation.
- Avoid normative judgment.
- Avoid mechanistic reasoning.
- Instead:
- Run a facilitated post-incident review.
- Not just the on-call responder.
- Have a neutral facilitator.
- Prepare with 1:1 interviews.
- Lots of incidents? Don’t do it each time.
- Language in questions matters.
- Ask how over why. “How did…”
- Ask after different viewpoints.
- Ask about what normally happens in a similar situation when there is no incident.
- See also Etsy’s Debriefing Facilitation Guide.
- Ask how things went right.
- How did we recover?
- What insights/tools/people were involved?
- Keep the review and todo planning separate.
- Keep mitigation talk out of the review. Plan a separate session for that.
- Helps keep focus on analysing what happened.
- Allows subconscious to work out mitigations in the background in between the two sessions.
- Run a facilitated post-incident review.

How Stripe Invests in Technical Infrastructure
Will Larson, Stripe
https://www.usenix.org/conference/srecon19emea/presentation/larson
- Dig out of firefighting trenches.
- Reduce concurrent work.
- Finish something useful.
- Automate.
- Eliminate entire catagories of problems (with creative solutions).
- If that doesn’t work? Hire!
- Also, don’t fall in love with firefighting.
- Listen to your users, especially when innovating.
- Benchmark against other similiarly-sized companies.
- Do surveys of your users.
- Prioritization:
- Order by Return on Investment (RoI).
- Don’t try without users in the room.
- Have a long-term vision.
- Avoiding the wrong solution to a problem:
- Validate with (potential) users first.
- Try the hard cases early/first.
- Investment strategy:
- 40% user asks.
- 30% platform quality.
- 30% “key initiatives”.
- These are somewhat arbitrary, adjust to your own needs/constraints.
Pushing through Friction
Dan Na, Squarespace
https://www.usenix.org/conference/srecon19emea/presentation/na
- Why does friction occur?
- Company growth.
- Example from aviation safety.
- 5 mandatory checklists – ignored.
- Alarm – ignored
- Normalization of deviance. Deviance becomes the norm.
- Friction inevitable with growth, but made worse by normalization of deviance.
- Solutions:
- Document single sources of truth.
- Update docs with acceptance criteria for work.
- Adopt processes to vet tech choices.
- Solicit the “What the fuck!?” of new hires.
- Long-term cultural fixes:
- Address hard truths kindly.
- Celebrate the glue work: https://noidea.dog/glue.
- Make Psychological safety paramount.
- Individuals:
- Develop your own sense of agency (see Drive by Daniel Pink).
- Strategies:
- Have important discussions face to face.
- Get to know people in other teams/departments.
- New idea? Try it once.
- See also https://talks.danielna.com.
Autopsy of a MySQL Automation Disaster
Jean-François Gagné, MessageBird (formerly booking.com)
https://www.usenix.org/conference/srecon19emea/presentation/gagne
- References MySQL High Availability at GitHub.
- Messagebird uses Orchestrator + ProxySQL.
- Solutions for split-brain:
- Kill on DB, lose data.
- Replay writes.
AUTO_INCREMENTgets in the way.- UUIDs are one possible solution.
- If doing UUIDs, consider monotonically increasing IDs instead, optimized for indexing.
Evolution of Observability Tools at Pinterest
Naoman Abbas, Pinterest
https://www.usenix.org/conference/srecon19emea/presentation/abbas
- Challenge #1: Usage growth.
- Avoid tool fragmentation.
- Observability is expensive, but good Return on Investment.
- At Pinterest everything going through kafka.
Fault Tree Analysis Applied to Apache Kafka
Andrey Falko, Lyft
https://www.usenix.org/conference/srecon19emea/presentation/falko
- Good intro talk for anyone unfamiliar with FTA.
- Resources at github.com/afalko/fta-kafka.
- SCRAM software used for the modeling.
Applicable and Achievable Formal Verification
Heidy Khlaaf, Adelard LLP
https://www.usenix.org/conference/srecon19emea/presentation/khlaaf
- Coq isn’t very usable.
- IEC 61508 the “Golden boy” safety standard.
- Safety justification triangle. (?)
- TLA+.